
TBM 335: "Simple" Dependency Coordination

A lot of teams approach dependencies like this:
“Put all of your projects in a spreadsheet!” Hurry. Hurry.
Try to “size” the work involved to help. Break it down. Make tickets. Estimate.
Prematurely converge on scope, way before people have had a chance to do any research, understand the problem, or have a moment to breath.
Trying to understand fine-grained engineer by engineer allocations.
Horse trade. 1:1 haggling.
Find who is overloaded. Try to ease the burden.
It almost never works.
Here is an alternative approach. Imagine I have three teams working in six-week cycles. Every team has three “slots” for focus: their main focus, their secondary focus, and some slack set aside for “ad hoc” work.
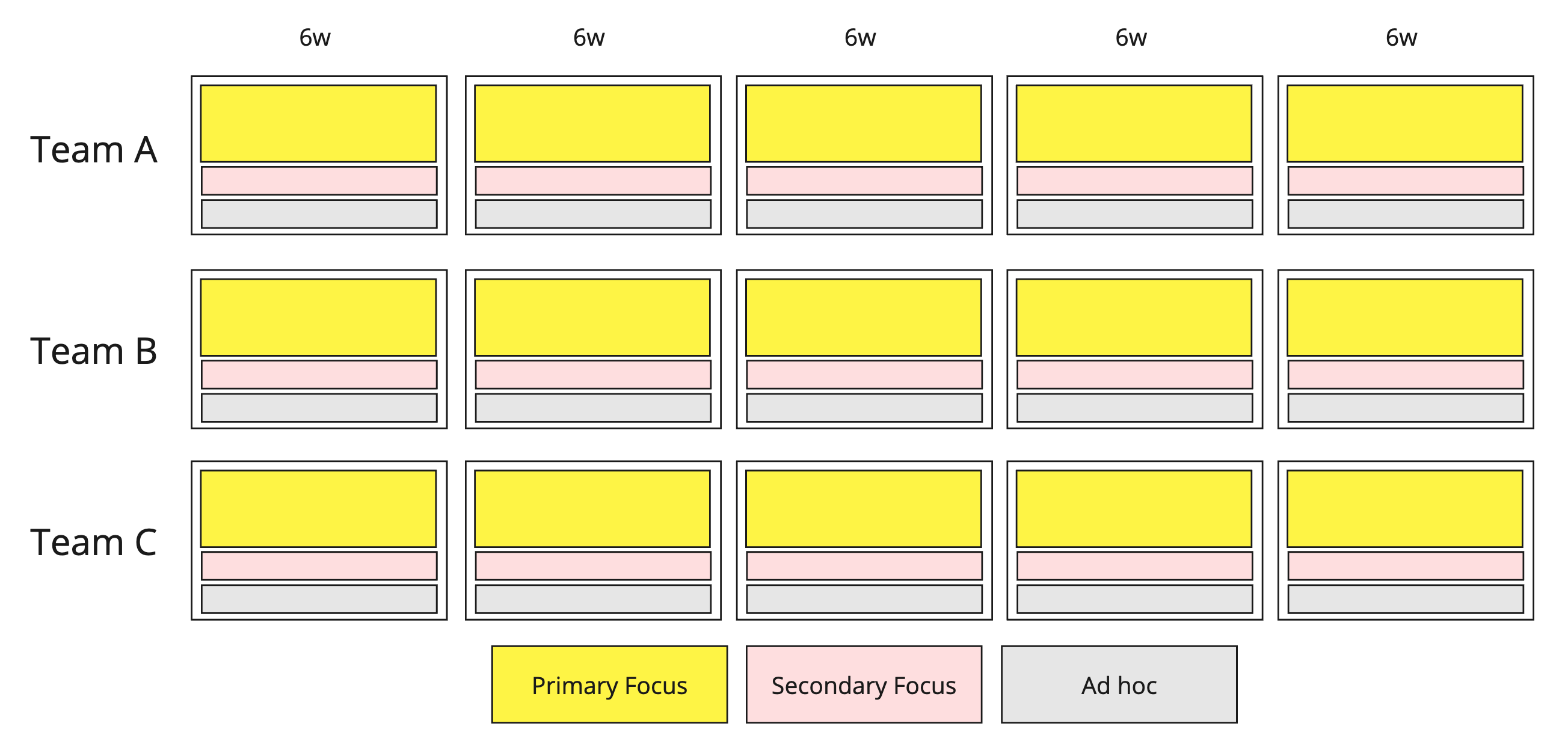
Everyone knows that if you try to juggle more than two things (plus ad hoc, interrupting work) as a team, you’ll start spending a lot of time on context switching. I don’t know many CFOs who would be comfortable knowing that 10–30% of salaries are going to context switching, so we stick with an enabling constraint of three slots.
Ideally, we’d like to see the primary focus occupy >50% of cognitive bandwidth (not time, bandwidth), and the remaining two areas <25%. If the ad hoc becomes >25%, you should probably make it the secondary focus or primary focus.
Now let’s take the Team Topologies “interaction modes” (see key concepts).
Collaboration. Teams work closely together to solve complex problems requiring shared ownership and innovation.
Facilitating. A team mentors or coaches another to improve capabilities or adopt new practices temporarily.
X-as-a-Service. One team provides a service to others, reducing dependencies and enabling focus on core tasks.
Here’s the big idea: the collaboration pattern has a much greater influence on the nature of the collaboration than a collection of tickets or back-of-the-napkin guesses.
Picture that Team A has two multi-bucket bets (with opportunities for continuous delivery and experimentation, of course). Team B and C don’t worry about figuring out every detail of the bet. Instead, they focus on collaboration patterns.
“How will we collaborate on that?”
(Note how Team A shifts focus level for the 6-week blocks.)

From here, we can use some broad heuristics:
If the collaboration approach is “Collaboration,” you must match the focus level of the originating team.
If the collaboration mode is “Facilitating,” it must go in the secondary focus lane.
If the collaboration mode is “X-as-a-Service,” you have to use your judgment about whether to use the secondary or ad hoc bucket.
The heuristics in action would end up looking like this:
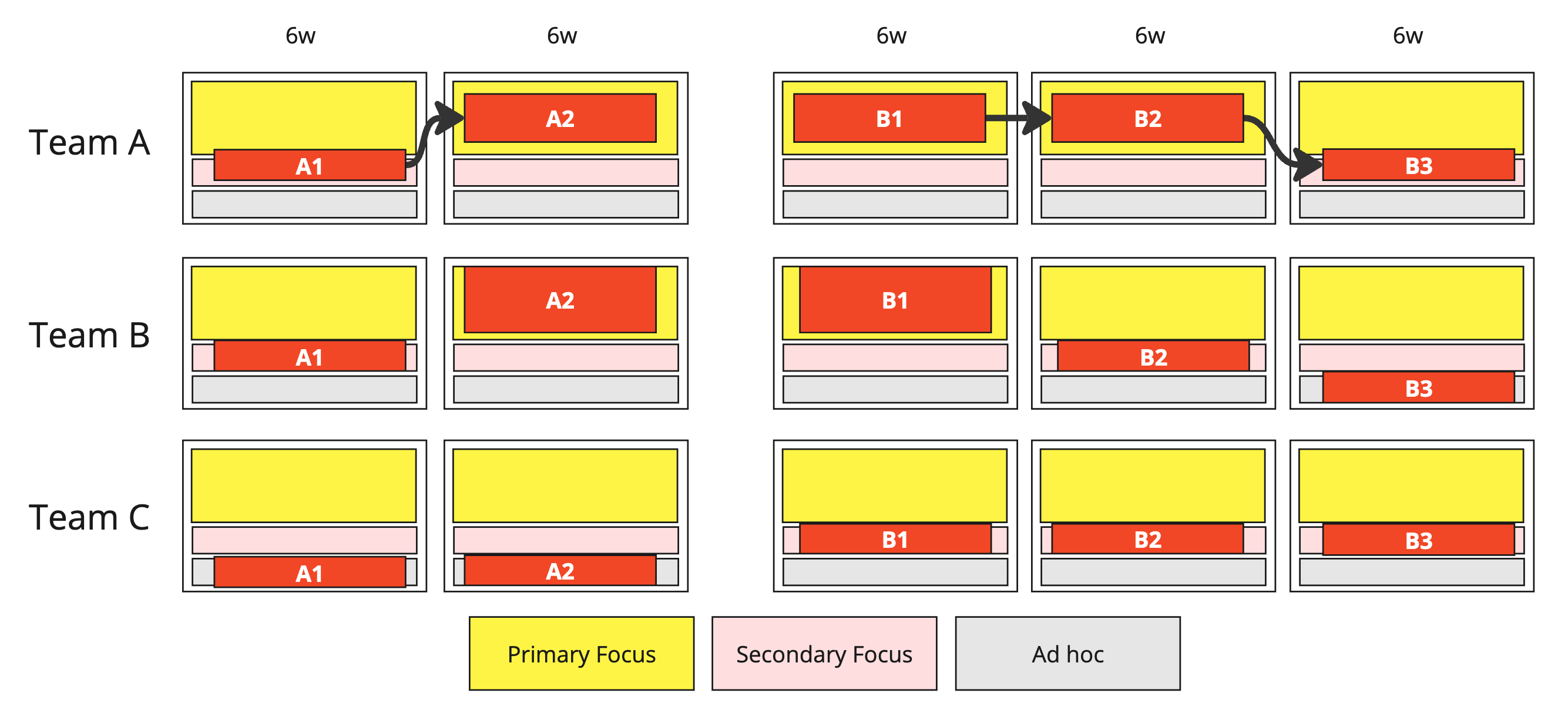
Together—the focus slot constraints, the collaboration models, and “rules”—help guide discussions to a better place. Instead of completely useless discussions like “Oh, is that story an X pointer or a Y pointer?” or “Can Meghan work 11% on Project A, 13% on Project B, and 22% on Project C?” you chat about how you will need to work and, when push comes to shove, what has a higher cost of delay.
Whenever I share this, someone will say something like:
I get this, but isn’t it too conservative? What if it might be possible to fit two items in the second focus area? What if the main focus area is 40%, not 50%? Why doesn’t it make more sense to load up every engineer with their own projects?
To which I respond:
Better to start conservative, and then fill in the gaps with small batches. It is better to have a bit of capacity left over and knock the main focus out of the park than it is to agree to peanut spread your focus and end up with mediocre progress on everything. How many times have you used wishful thinking to pack everything in, and ended up with nothing to show for it?
Now…how many times have you been more conservative with your focus, executed well and with less effort than expected, filled in the gaps with pebbles, and gotten in trouble? What is that ratio? In my career the ratio is something like 10:1 try too much vs. getting in trouble. OK, let’s try this as an experiment and see what happens.
Obviously, limiting the deep for certain dependencies is ideal. Using this approach helps you make more sense of the issue.
Hope this helps.
Aside, at the day job (Dotwork), we help companies implement “quirky” approaches like this that mainstream tool providers avoid because it doesn’t match the middle of the bell curve. Always feel free to reach out if you want to do something weird at your company. We can help.
I like the argument for focus, and for teams supporting one bet at a time by collaboration or facilitation!
The part about dividing that focus over a primary and secondary seems to dilute the argument - I'm curious about the rationale behind it.
The treatment of ad hoc work doesn't resonate with me. It clearly wasn't the focus of this essay, and perhaps I read more into it, but...
If ad hoc work is anything like 25% of a teams capacity, they're in trouble. There are a host of predictable dysfunctions lurking! Formation of an 'ad hoc' team, for example. Ignoring the source of so much 'ad hoc', allegedly valuable work, for another. Because ad hoc work is not coherent, it usually imposes much higher switching costs than 'merely' responding to a change in priorities. And so on!
Thought provoking essay, John, thank you!
Oh, I never think using that to match different teams. In my company, I used something very similar to match feature prioritization and inversion of priorities (when a low priority becomes inadvertently high priority). Here how it goes (the actual process is more adhoc when I'm using it, but that's the on paper theory):
Each team has 3 lanes:
* (C)ollaboration lane is for a single high priority item with 1 item and take up to 80% of the team time. It's also usually the goal of the team.
* (F)affiliation lane can have between 0 and 2 items and cannot take more than 60% of the time of team, or 40% per item.
* (X)-as-a-service lane is at least 10% and never more than 20% total and is purely adhoc work: support, janitor, etc. it's never zero but never planned either.
So, for example, you can have an iteration composed of 1 C task at 80% and the rest in X. Or you can have 1 C at 40%, 2 F at 25% each and 10% on X. Note that the % is more a rule of thumb and rarely mentioned directly. The team mostly decide what is going in lane C, if they want to add anything to lane F, and how much time they want to consecrate to lane X (minimum 10%, always at least 20%).
Now, some additional rules:
1. The team must follow the interaction mode of each lane for each task. C means you sit down with the client, check regularly with them and really focus on them, while F is more spot isolate,with spot checks, while X must be asynchronous (tickets, etc.).
2. Features go from C to F to X, which determines also in which lane that feature can be worked on. If a feature is at C, and you already an item in lane C, you most choose which one is worked on. Cannot be both at the same time.
3. If any feature in F or X is starting to take more than the limit of time for its category, it must be upgraded. That's similar to the SRE principle of putting a feature back to the dev team when it doesn't reach their SLA. Such upgrade also force both precedent rules to activate: if the lane above is full, something must yield, and the work must be done in the interaction mode of the lane.
E.g. The team is working on a new feature with the client when a major problem happens. At first, their firefighter for this sprint is trying to figure it out, but this doesn't work. He asked for help and the feature is upgrade to the F lane, which is free. The devs, now in pair, contact the client and asked to do a small investigation meeting with them, explaining the problem. The investigation leads to find some important corruption. The team decides to upgrade the bug to the C lane, give their apology to the client of the initial feature, and give now their main focus to the important problem.
OK, a big long as a comment, hope you don't mind too much, I promise to write this down properly one day, but feel free to let it inspire you in any of your "weird" experiment. Just give me some feedback on how it goes if you end up using it.